


Le développement des outils d’intelligence artificielle est une révolution scientifique de premier ordre. Dans les premiers temps, il est apparu que la double course de représente cette révolution, celle des modèles et celle des microprocesseurs donnerait une nouvelle avance aux USA sur le monde. Comme le détaille cet article au sujet des modèles d’IA, il n’en est rien. Non seulement la Chine avance mais elle accélère et sa force de frappe devient très impressionnante. Comme nous l’avons souligné dans d’autres secteurs technologiques, la force de la Chine est de pouvoir avancer sur plusieurs pistes technologiques en parallèle, afin d’être la première à développer industriellement celle qui marche. Sur le plan des puces, la situation est similaire. Le dernier bastion des puces états-unienne de haute finesse de gravure devrait être brisée début 2026, à l’occasion de la sortie du nouveau Huawei Mate 80, avec une puce Huawei entièrement chinoise gravée en 3 nm. C’est en tous cas ce qu’annonce la presse spécialisée et qui fait trembler ces jours-ci les marchés financiers de la tech occidentale, et en premier lieu la valeur vedette Nvidia. (Note de Franck Marsal pour Histoire&Société).
La courbe imprévisible
L’innovation ne suit jamais un scénario préétabli. Elle s’accélère, trébuche et surprend. Il y a deux ans, une note de service de Google qui a fuité avertissait que les modèles open source finiraient par éroder la protection qui semblait protéger les développeurs de LLM propriétaires. Pendant un certain temps, les développeurs propriétaires ont défié cette prophétie en prenant de l’avance en termes de capacités et de réputation. Aujourd’hui, cette note semble plus juste que les projections les plus pessimistes de l’époque. Plus important encore, rares sont ceux qui auraient pu prédire le type et le nombre d’acteurs qui saisiraient cette opportunité.
Il y a un an, l’idée d’un leadership chinois dans le domaine de l’IA semblait invraisemblable. Notre série d’articles, à commencer par celui intitulé « Une vague silencieuse : l’essor des innovateurs chinois en matière d’IA », a suscité plus de doutes quant à son contenu que d’avis sur le paysage actuel. Même après DeepSeek, le monde considérait que les modèles chinois étaient dérivés ou copiés, avec des affirmations exagérées et invérifiables, et que leurs laboratoires étaient limités par les sanctions et les coûts.
Cette opinion semble désormais dépassée. À la mi-2025, les développeurs chinois ont publié plus de LLM publics que quiconque. Ils ont commencé à dominer les classements de téléchargement. DeepSeek, Qwen, MiniMax et Kimi ne sont plus des noms marginaux. Ce renversement de tendance a commencé avant les dernières versions apparues ces dernières semaines. Lorsque nous avons commencé à rédiger cet article en début de semaine, huit des dix modèles ouverts les mieux classés étaient chinois. Si l’on en croit les chiffres, l’écart s’est depuis creusé ! Alors que nous écrivions cet article, vendredi dernier, nous avons reçu le premier modèle open source, celui de Kimi, qui prétend surpasser les capacités des meilleurs modèles propriétaires sur une liste de benchmarks populaires. Le changement ne concerne plus seulement les algorithmes. Il concerne la manière dont l’économie de l’IA va connaître d’autres changements en 2026.
La cascade vers l’ouest
Avant d’aborder les détails des changements en cours, examinons les preuves de leur acceptation. Pour une multitude de raisons nationalistes, idéalistes, historiques et autres, les modèles chinois ont suscité le mépris des médias populaires en raison de leurs coûts, des questions de sécurité et de confidentialité, de l’authenticité des innovations revendiquées et de la légalité du matériel qui aurait pu être utilisé. Aucune de ces questions n’a reçu de réponse adéquate ou satisfaisante pour tous, mais dans de nombreux milieux occidentaux, le scepticisme ne s’est pas arrêté à la discussion. Il s’est arrêté à l’utilisation.
Selon les médias, les ingénieurs de Cursor s’appuient désormais sur des modèles ouverts chinois pour alimenter leurs agents de génération de code. Le SWE-1.5 de Cognition, à la pointe de la technologie, a été discrètement construit sur un modèle de base chinois. Airbnb, qui devait initialement s’orienter vers OpenAI, utilise désormais Qwen d’Alibaba pour ses bots de service client. Il y a deux semaines, son directeur général, Brian Chesky, l’a qualifié de « rapide, performant et bon marché ». Chamath Palihapitiya, fondateur de Social Capital, a déclaré que certaines de ses entreprises avaient transféré plusieurs charges de travail d’Anthropic et d’OpenAI vers Kimi de Moonshot, le qualifiant de « bien plus performant et beaucoup moins cher ».
On peut rejeter les récentes informations selon lesquelles les modèles chinois surpasseraient les autres modèles dans le domaine du trading cryptographique et boursier (tests distincts rapportés ici et ici) comme étant ponctuels, idiosyncrasiques et sans historique suffisamment long. Cependant, les preuves de parité se multiplient.
Ce que l’on observe dans l’adoption de la production par un petit nombre d’entreprises américaines a des implications à long terme. Les modèles autrefois rejetés pour des raisons de sécurité ou de fiabilité sont désormais à la base d’entreprises qui ne changeraient pas leurs préférences sans avantages trop importants pour être ignorés. Il est clair que les doutes concernant les fuites par des portes dérobées ou les subventions publiques s’estompent lorsque l’efficacité l’emporte.
Les modèles chinois établissent de nouvelles normes et de nouveaux standards de transparence. Chaque publication chinoise importante s’accompagne d’un document, d’un benchmark et de pondérations qui peuvent être téléchargés par tout le monde sans frais ni conditions particulières.
Architectures en mouvement
Au cœur de cette vague se trouve un principe : faire plus avec moins. La technologie qui sous-tend cette nouvelle vague est le Mixture of Experts (MoE). En résumé, les modèles chinois ont tous adopté le MoE. Ils innovent désormais dans ce cadre, créant sans cesse de nouvelles vagues d’efficacité. En revanche, quelques modèles occidentaux clés, comme Claude d’Anthropic, résistent totalement au MoE. D’autres l’ont adopté, mais sans accorder la même importance à l’efficacité. En Chine, la course est désormais lancée. Le nombre de nouvelles orientations, la rapidité des annonces et la qualité de l’exécution sont époustouflants. Le reste de cette section peut être ignoré par ceux qui ne s’intéressent pas aux détails généraux du MoE.
Pour ceux qui s’y intéressent, cela aide à comprendre le contexte. La plupart des observateurs suivent le développement de l’IA dans les grandes lignes. La première vague, en 2023, concernait la taille. C’était une course à la création de modèles toujours plus grands. La deuxième vague, en 2024, concernait le raisonnement, les techniques de « chaîne de pensée » étant devenues la norme. Beaucoup ont rapidement adopté ce changement. Certains, comme Llama et Mistral, ont raté le coche et en ont subi les conséquences durables. La tendance générale de la période actuelle est ce mélange d’experts.
Cette méthode, qui trouve son origine chez Google, est une stratégie d’efficacité. Le MoE transforme un modèle unique et massif en une fédération de modèles plus petits. Au lieu d’activer tous les paramètres pour chaque requête, le MoE n’active que les experts nécessaires à une tâche donnée. Les autres restent inactifs, ce qui permet de réduire les coûts sans diminuer l’échelle totale.
Le génie du MoE réside dans le fait qu’il invite à la variation. Une fois qu’un modèle devient un ensemble de spécialistes plutôt qu’un monolithe unique, chaque laboratoire peut décider comment répartir et affecter ces spécialistes. Certains les regroupent par compétence, un groupe d’experts pouvant être dédié à la langue, un autre aux mathématiques et un autre encore au raisonnement. D’autres peuvent répartir les experts en fonction de leur niveau de compétence, les experts légers pour les réponses rapides, les experts lourds pour les tâches complexes. Certains, comme MiniMax, changent d’expert de manière dynamique au sein d’une même requête, traitant chaque étape comme un problème de routage distinct. DeepSeek regroupe ses experts de manière hiérarchique, transmettant les résultats partiels vers le haut d’un arbre jusqu’à ce que la meilleure couche complète la réponse. Qwen recherche l’efficacité grâce au « sparse gating », qui permet à plusieurs petits experts de partager des créneaux d’activation afin qu’aucun calcul ne reste inactif. Kimi, le plus récent, mélange le routage modulaire avec une attention au contexte long, faisant appel à différents experts pour chaque étape d’une chaîne de raisonnement.
Ces choix de conception peuvent sembler obscurs, mais ils se traduisent par des gains visibles. Des modèles plus rapides. Des coûts réduits. Des fenêtres contextuelles plus longues. En une génération, Minimax a fait preuve d’une extrême parcimonie, atteignant des performances de pointe en n’activant que 10 des 230 milliards de paramètres. Kimi combine le MoE avec un nouveau mécanisme d’attention qui semble croître de manière linéaire, contrairement aux transformateurs traditionnels qui croissent de manière quadratique, promettant des gains extrêmes pour les contextes longs. DeepSeek est en train de repenser la logique même du routage des experts, tandis que Tencent a récemment surpris tout le monde avec le concept de poids non fixes.
Les équipes chinoises ont montré qu’il n’existe pas de recette unique pour le MoE, mais seulement une infinité de façons de combiner les experts. Chaque permutation permet de réaliser un petit bond en avant en termes d’efficacité ou de profondeur de raisonnement.
La leçon plus générale à tirer est que le MoE prouve à quel point le domaine est encore loin des limites théoriques du transformateur. Le rythme des progrès montre que les architectures actuelles sont loin d’être optimisées. La croyance dominante selon laquelle la taille seule garantit le progrès est dépassée. Le MoE nous rappelle que ce sont les heuristiques, et non les lois, qui guident cette science. Il n’y a pas de voie toute tracée. Les percées en matière d’efficacité peuvent provenir du routage, de la rareté, de la mémoire ou de quelque chose qui n’a pas encore été imaginé. La seule certitude est que plus on explore de méthodes, plus la probabilité d’une percée est élevée. La Chine est actuellement au centre de cette exploration.
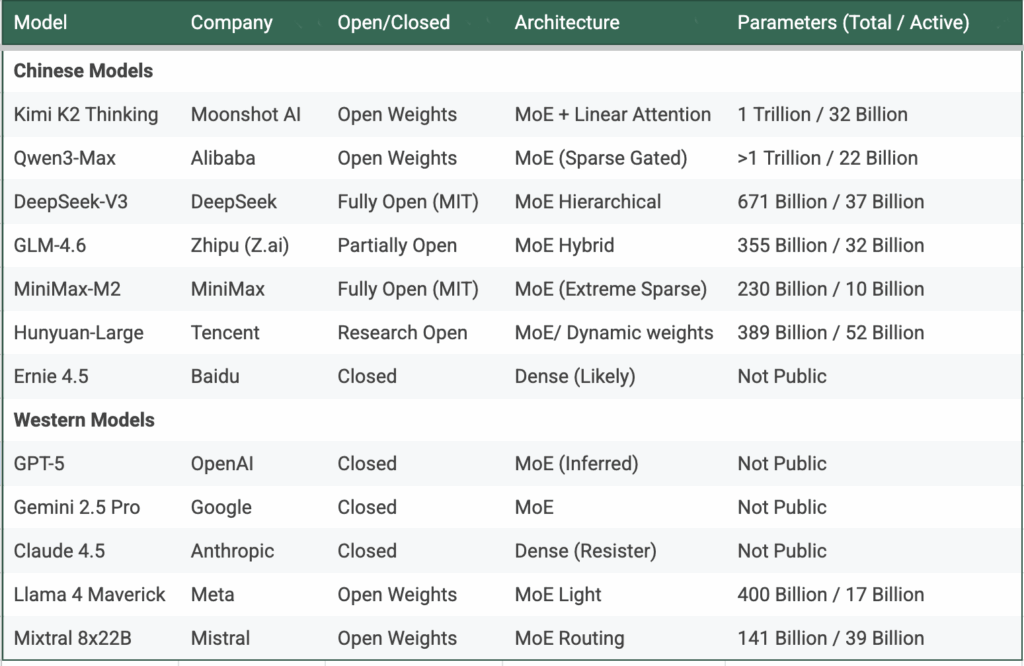
Économie de l’ouverture
L’open source ne signifie pas zéro revenu. Il modifie simplement la provenance des revenus.
L’exécution d’un modèle de grande envergure nécessite toujours des capacités de calcul. L’hébergement d’un modèle ouvert à l’échelle d’une entreprise nécessite des racks de GPU ou un accès à des capacités cloud. Le coût d’investissement passe de la licence à l’infrastructure. Pour la plupart des utilisateurs, ce compromis favorise le paiement du créateur du modèle pour l’accès à l’API plutôt que l’auto-hébergement.
C’est là le modèle économique caché de l’ouverture. Cognition gratuite, commodité payante.
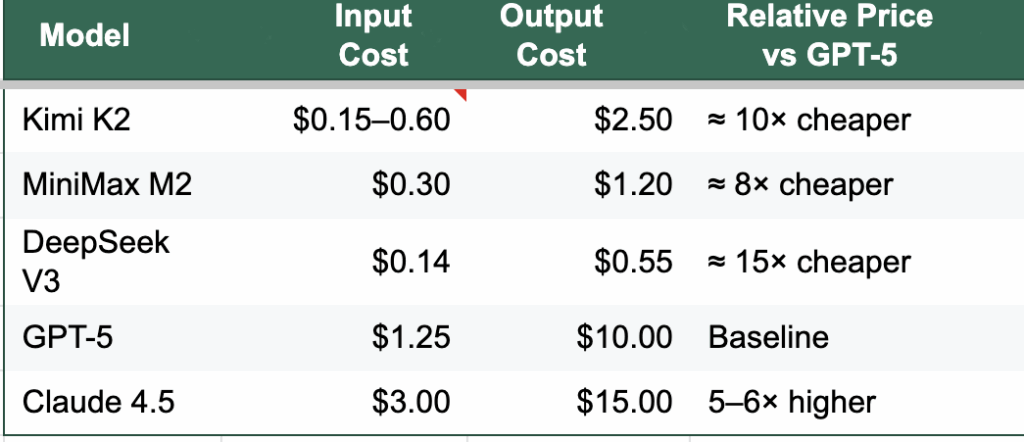
Le modèle à 671 milliards de paramètres de DeepSeek a coûté moins de six millions de dollars, et le même chiffre circule pour le dernier modèle Kiimi, qui rivalise avec le meilleur modèle d’OpenAI dans les benchmarks populaires. Que les coûts de formation réels soient ceux annoncés ou plusieurs fois supérieurs, ces modèles sont formés de manière extrêmement rentable. En conséquence, les équipes chinoises peuvent facturer quelques centimes et continuer à dégager des marges. Leurs API sont dix à cinquante fois moins chères que leurs équivalents occidentaux. Elles ont besoin de moins d’utilisateurs pour atteindre le seuil de rentabilité.
Le coût de la cognition (par million de jetons)
La nouvelle brutalité
La concurrence est passée du symbolique à l’existentiel. Les laboratoires chinois commercialisent de nouveaux modèles toutes les quelques semaines, souvent avec des gains mesurables. Comme nous l’avons constaté ces derniers jours, certains développeurs de modèles occidentaux ont commencé à faire pression pour obtenir des protections politiques. La conséquence réelle, cependant, est que compte tenu de l’intensité des innovations et des progrès, aucun des grands centres d’innovation régionaux ou des équipes d’entreprises ne peut se permettre de ralentir ses efforts. Si certains échouent lamentablement en matière de coûts, ils devront trouver d’autres innovations gagnantes en termes de capacités.
Il n’est pas surprenant que Jensen Huang estime que la Chine a quelques nanosecondes de retard en matière d’IA. Même avec des restrictions matérielles, son moteur d’innovation ne montre aucun signe de faiblesse. Certains diront que ces restrictions ne font que renforcer leur concentration sur l’efficacité.
À première vue, nous pensons que l’amélioration de l’efficacité multiplie la demande. Chaque amélioration du coût des modèles invite à de nouvelles utilisations : génération de vidéos, recherche multimodale et agents autonomes. Une seule vidéo de trente secondes peut consommer plus de puissance de calcul que des pages d’inférence textuelle. Cela dit, nous serons les premiers à croire en une telle hypothèse simplement sur la base de « sentiments », de « l’histoire » ou d’une loi au nom fantaisiste.
Alors que nous nous approchons de 2026, deux courses effrénées s’intensifient. L’une concerne le développement des modèles décrits ci-dessus, l’autre la conception de puces personnalisées. Les acteurs de la course aux puces, comme décrit dans la partie centrale de cette note, sont les plus grands noms mondiaux du matériel informatique, dotés des budgets les plus importants. Et l’annonce faite il y a quelques jours par Google concernant son TPU Ironwood montre que lui aussi peut réserver des surprises que personne ne peut prévoir.
La vérité est simple : les prédictions sont dangereuses. Personne n’avait prévu que les poids ouverts chinois deviendraient les leaders mondiaux de référence. Personne ne peut savoir quelle innovation dominera l’année prochaine.
La seule règle durable est la flexibilité. Chez GenInnov, nous nous rappelons sans cesse qu’il faut tirer les leçons des événements au fur et à mesure qu’ils se déroulent, plutôt que de s’attendre à ce qu’ils suivent un chemin particulier. L’investissement fondé sur des preuves exige de rester flexible dans la sélection ou la sortie, et de continuer à apprendre, quelle que soit la complexité apparente.
Cet article a été publié pour la première fois sur GenInnov et est republié avec autorisation. Lire l’original ici.

Views: 18


Pierre Nouzier
Forte intéressante analyse provenant d’un fond d’investissement, avec semble-t-il un point aveugle ou une donnée cachée : l’énergie nécessaire à toutes ces merveilles, à moins qu’elle soit sous-entendue dans l’analyse des coûts ? Je ne sais. Car l’IA, dévoreuse de données, mobilise de plus en plus de ces « data centers » monstrueux qu’il faut alimenter en électricité et dont il faut évacuer les calories (le problème se pose dans la région où j’habite). Les pétro-monarchies peuvent aligner les milliards pour l’IA, il faut aussi aligner les kWh. Nul doute que les chinois soient conscients du problème !